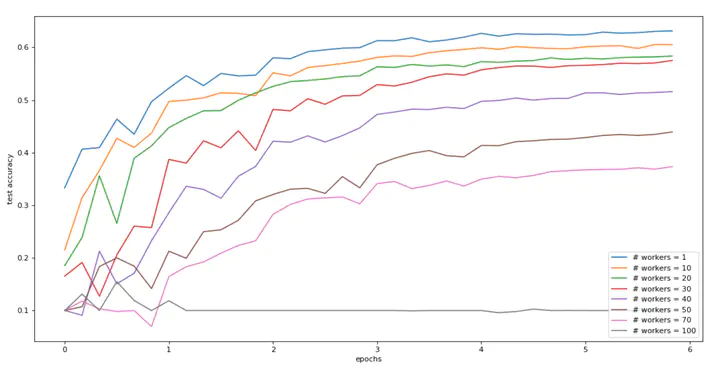
 Test Accurancy with different delay
Test Accurancy with different delayTraining large machine learning models on large datasets is notoriously computationally heavy. When multiple workers are available, a common algorithm to perform the training is Asynchronous Stochastic Gradient Descent (ASGD), wherein gradients of the loss on mini-batches are computed by workers and added to the model weights by the server. The workers are not fully synchronized with the server, which enables speedup by parallelization. However, this asynchronicity causes the gradients to be computed with a “delay” compared to the actual model on the server. In this work, we simulate a simple version of ASGD allowing us to study the effect of delay only. Based on experiments on real-life data, we draw the following insights on the behavior of ASGD. We confirm the adverse effect of delay on the training process. We observe that past a certain threshold, delay may prevent training entirely. For large delays, using momentum improves the performance of ASGD dramatically.